Overview
Realizing the full value of AISDLC does not happen overnight. Without clear markers, teams risk mistaking activity for progress. To avoid this, we identified three maturity stages that reflect how AISDLC adoption realistically unfolds. They are not rigid milestones, but honest signposts: are we getting better at this, and are we getting better at the right things?
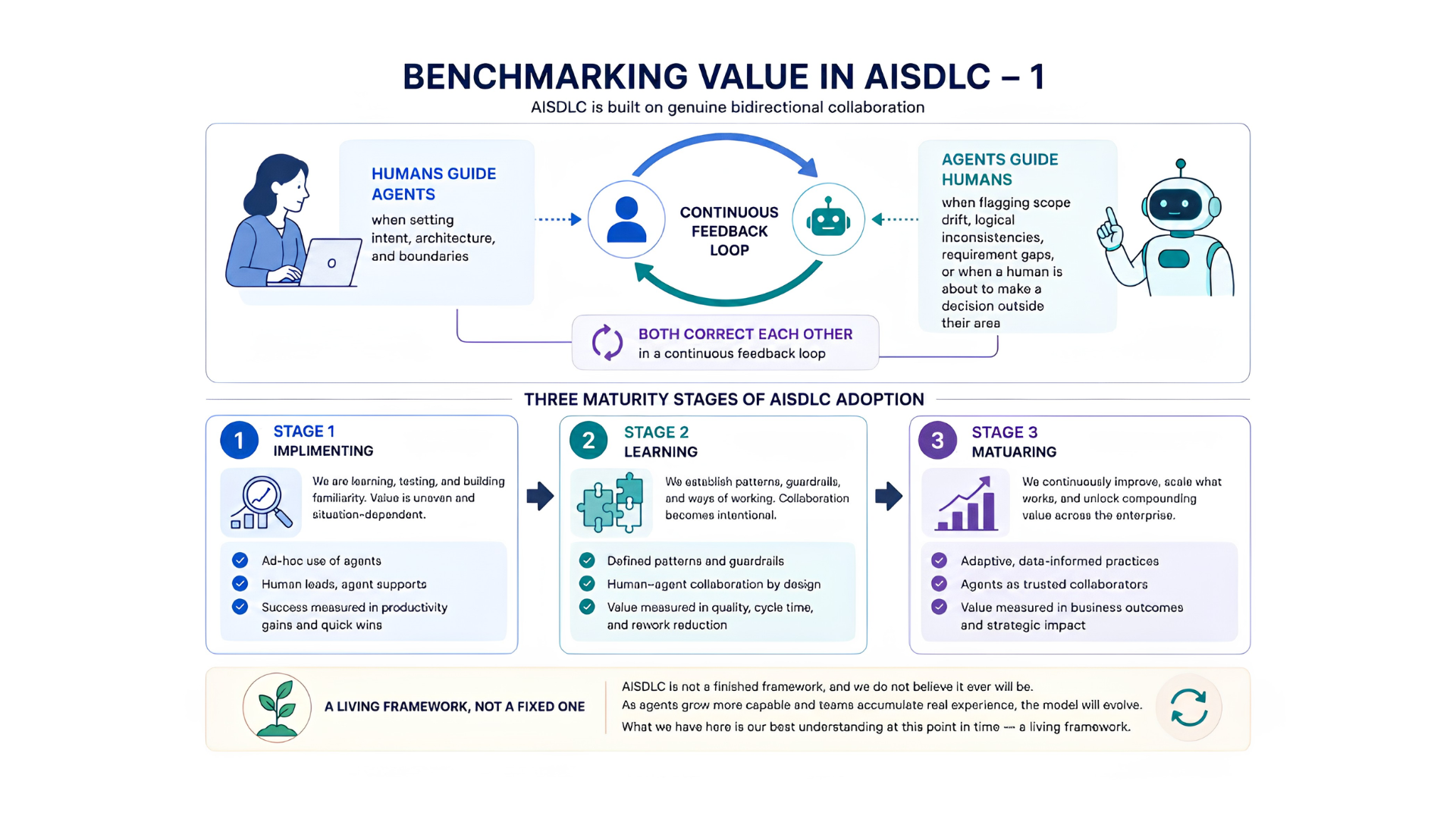
The bidirectional Framework
AISDLC is not a tool you install — it is a relationship you build. The measurement framework exists to make that relationship legible.
As we discussed in our insight papers before, Aventude AISDLC is fundamentally built on bidirectional collaboration where:
How the collaboration works in both directions
- Humans guide agents when setting intent, architecture, and boundaries.
- Agents guide humans when flagging scope drift, logical inconsistencies, requirement gaps, or when a human is about to make a decision outside their area.
- Both correct each other in a continuous feedback loop.
It is also worth saying clearly: AISDLC is not a finished framework, and we do not believe it ever will be. As agents grow more capable and teams accumulate real experience, the model will evolve. What follows is our best understanding at this point in time — a living framework, not a fixed one.
STAGE 1
Implementation — Months 1 to 3. Adoption quality and error reduction, not speed.
STAGE 2
Learning — Months 4 to 9. Efficiency and quality gains become measurable.
STAGE 3
Maturing — Month 10 onwards. AISDLC is the operating model, not an experiment.
LIVING FRAMEWORK
Benchmarks are run at regular intervals regardless of how things feel.
Stage 1 — Implementation (Months 1–3)
The most valuable thing happening in Stage 1 is not shipping — it is the team developing judgment about what agents can and cannot reliably do.
Teams are integrating agents into their existing SDLC for the first time. The instinct is to measure productivity immediately — resist it. Initial velocity may appear flat or slightly lower than before. This is normal and expected. Agents introduce a new kind of overhead: prompt crafting, output review, and correction. The benchmark goal here is adoption quality and error reduction, not speed. Speed comes later.
We are thinking of this stage 1 as the period where the team is developing a new professional instinct. Just as a developer new to a codebase reads more than they write at first, a team new to AISDLC corrects more than it delegates. That is healthy. The goal is to leave stage 1 with a clear, documented diagram of where agents help, where they fall short, and what good agent output looks like in your specific context.
Stage 1 outcome
Agents are introduced. Humans are learning when to trust, when to correct, and how to prompt effectively. Expect friction before flow.
Benchmark matrix — Agent Performance in Pods
For each row, if you are missing the target, the "what it tells you" column is not commentary — it is your diagnostic starting point.
| Agent / Area | What to measure | Target | What it tells you if you miss it |
|---|---|---|---|
|
Requirements Agent |
% of requirement drafts accepted without major rewrites | 30–50% accepted as-is | Agent is not capturing intent correctly. Run a structured prompt review — the problem is usually missing context or unclear scope handoff from the human. |
|
Requirements Agent |
% of requirements with ambiguities flagged before architecture begins | 60%+ flagged proactively | Agent is passing incomplete specs downstream. Gaps are being discovered too late, in dev or test, where they cost more to fix. |
|
Architecture Agent |
% of architecture proposals that survive human review without structural changes | 25–40% accepted as-is | Agent lacks sufficient context about constraints, non-functionals, or existing system. Humans need to front-load more constraint documentation. |
|
Architecture Agent |
% of architecture decisions traceable back to a documented requirement | 85%+ traceable | Agents are building without grounded intent. Traceability gaps here become rework in test or post-deploy. |
| Dev Agent | % of agent-generated code accepted without significant change | 20–35% accepted as-is | Prompts or architectural context passed to the dev agent is insufficient. Check the handoff between architecture and dev agent. |
| Test Agent | Is test generation running in parallel with dev, not after? | Yes, by week 4 | Sequential test-after-dev means the test agent is not yet integrated into the cycle. Bugs will cluster at the end of the sprint rather than surfacing continuously. |
| Test Agent | Bug count per sprint split by source: agent-introduced, human-introduced, missed by test agent | Tracked and split by source | Without this split you cannot tell whether bugs are coming from weak dev output, weak prompts, or weak test coverage. All three look the same if you only count total bugs. |
| Agent Sync | How often does the dev agent receive architecture context that is incomplete or contradicts the requirements? | Less than 15% of tasks | This is your primary sync failure signal. High rates mean agents are operating in silos — the requirement-to-architecture-to-dev handoff chain is broken. |
| Agent Sync | Time between a requirement change and that change being reflected in architecture and test scope | Same sprint | Requirement drift not propagated is the most common source of late-stage rework in Stage 1. If agents are not updating in sync, you are accumulating hidden debt. |
| Human Oversight | % of agent handoffs between stages that a human reviews before the next agent proceeds | 80%+ reviewed | At Stage 1, trust has not been earned yet. Unreviewed handoffs compound errors across agents. A bug introduced by the requirements agent and not caught before dev can propagate through all remaining stages. |
| Override Log | % of human overrides that identify which agent caused the correction, not just that a correction happened | 80%+ agent-attributed | Without agent attribution you cannot improve individual agents. You only know the system has gaps, not where. |
Benchmark matrix — Human Interactions in Pods
| Measure | What to ask / track | Target | What it tells you if you miss it |
|---|---|---|---|
| Human Sentiment in the Pod | Weekly pulse survey (1–5): "The agents in my pod are making my work easier, not harder." Tracked per pod, not averaged across the whole team. | 3.0+ by week 4, trending up by week 8 | A flat or declining score means the team is absorbing agent overhead without seeing return. The problem is usually poor handoff quality or agents generating output the human still has to rebuild from scratch. If one pod scores significantly lower than others, investigate that pod specifically — do not let a high-scoring pod mask a struggling one. |
| Human Confidence in Agent Output | Weekly pulse survey (1–5): "I feel confident reviewing and correcting agent output in my area without it slowing me down." | 3.0+ by week 6 | Low confidence means humans are not yet able to evaluate agent output critically. Humans who lack confidence either over-correct everything or approve things they are unsure about. Neither is safe at Stage 1. |
| Lead Time: Requirement to Dev-Ready | Days from a requirement being finalised to the dev agent receiving a complete, approved brief. | Baseline in weeks 1–2, then improve or hold steady | If lead time is growing, the handoff between requirements and architecture is the bottleneck. A brief that takes longer to produce with agents than without is a clear signal the process needs restructuring, not just better prompts. |
| Lag Time: Bug Discovery to Resolution | Days from a bug being flagged by the test agent or human reviewer to it being resolved and closed. | No worse than pre-AISDLC baseline | A growing lag means bugs are piling up faster than the team can process them. At Stage 1 this usually means the test agent is running too late in the cycle — bugs are being found in batches rather than continuously. |
| Review Inventory (Work in Queue) | Count of agent outputs sitting unreviewed by a human at the end of each sprint — broken down by stage: requirements, architecture, dev, test. | Zero unreviewed outputs carried into the next sprint | Carried inventory is hidden risk. Every unreviewed agent output from the current sprint becomes a compounding assumption in the next. A growing queue means humans are the bottleneck — which is a resourcing and process design problem, not a technology one. |
A note on override rates: A high human override rate at this stage is not a failure — it is evidence the team is engaged and critically reviewing agent output. The real danger is the opposite: very low override rates combined with poor output quality, which means the team is rubber-stamping. If overrides drop below 20% in the first six weeks without a corresponding quality improvement, investigate immediately.
Stage 1 — Readiness Checklist
Run a structured retrospective at the 6-week and 12-week marks. For each dimension in the matrix, mark it green (at target), amber (within 20% of target), or red (not tracked or significantly off). Use the checklist below as your readiness gate before advancing to Stage 2.
- The team can articulate which tasks agents are currently handling and which they are not.
- Override rates are tracked and at least 80% of overrides have a documented reason.
- Developer sentiment score is at or above 3.0 on average.
- Bug injection rate has not worsened compared to the pre-AISDLC baseline.
- At least one team member has been designated as the AISDLC practice lead.
- A shared prompt library has been started, even if it only contains a handful of entries.
- The team has agreed on a short list of tasks agents are not permitted to handle autonomously.
The single most valuable output of Stage 1
The single most valuable output of Stage 1 is not code — it is the log of overrides and corrections. That log is the raw material from which your team builds its agent delegation strategy in Stage 2. Teams that skip this discipline arrive at Stage 2 without a map.
The discipline built in Stage 1 does not disappear. It compounds. Every override logged, every correction documented, is an investment the team will draw on long after the early friction is forgotten.