Översikt
Att realisera det fulla värdet av AISDLC sker inte över en natt. Utan tydliga markörer riskerar team att förväxla aktivitet med framsteg. För att undvika detta identifierade vi tre mognadsstadier som speglar hur AISDLC-adoption realistiskt sett utvecklas. De är inte rigida milstolpar, utan ärliga vägvisare: blir vi bättre på detta, och blir vi bättre på rätt saker?
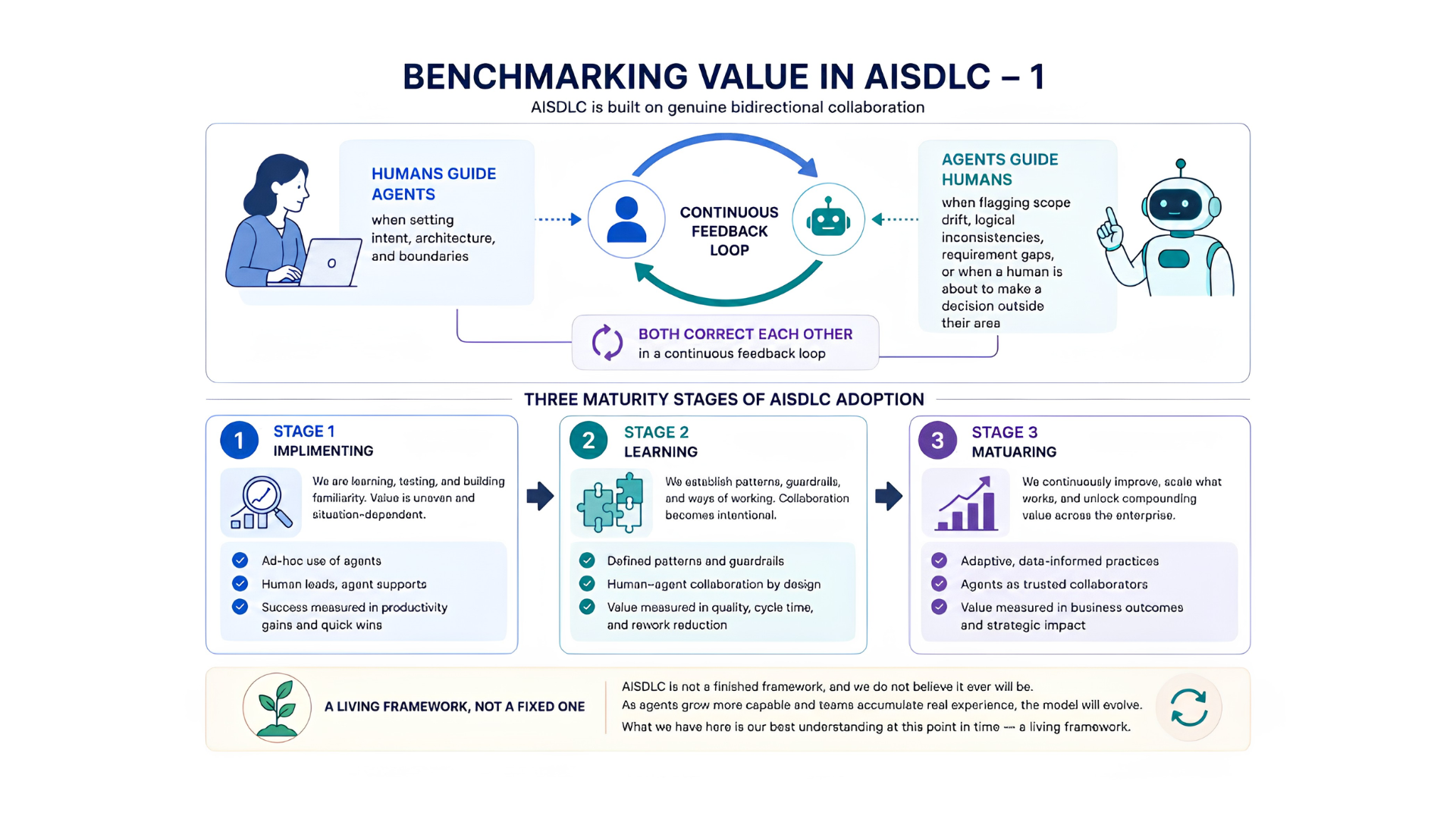
Det dubbelriktade Ramverket
AISDLC är inte ett verktyg du installerar — det är en relation du bygger. Mätramverket finns till för att göra den relationen begriplig.
Som vi diskuterade i våra insiktsartiklar tidigare är Aventude AISDLC fundamentalt byggt på dubbelriktat samarbete där:
Hur samarbetet fungerar i båda riktningarna
- Människor vägleder agenter när de fastställer intentioner, arkitektur och gränser.
- Agenter vägleder människor när de flaggar omfattningsdrift, logiska inkonsekvenser, kravluckor, eller när en människa är på väg att fatta ett beslut utanför sitt område.
- Båda korrigerar varandra i en kontinuerlig feedbackloop.
Det är också värt att säga klart: AISDLC är inte ett färdigt ramverk, och vi tror inte att det någonsin kommer att bli det. I takt med att agenter blir mer kapabla och team samlar verklig erfarenhet kommer modellen att utvecklas. Det som följer är vår bästa förståelse vid denna tidpunkt — ett levande ramverk, inte ett fast.
STADIUM 1
Implementering — Månader 1 till 3. Adoptionskvalitet och felminskning, inte hastighet.
STADIUM 2
Lärande — Månader 4 till 9. Effektivitets- och kvalitetsvinster blir mätbara.
STADIUM 3
Moget — Månad 10 och framåt. AISDLC är driftsmodellen, inte ett experiment.
LEVANDE RAMVERK
Benchmarks körs vid regelbundna intervaller oavsett hur det känns.
Stadium 1 — Implementering (Månader 1–3)
Det mest värdefulla som sker i Stadium 1 är inte leverans — det är teamets utveckling av omdöme om vad agenter pålitligt kan och inte kan göra.
Team integrerar agenter i sin befintliga SDLC för första gången. Instinkten är att mäta produktivitet omedelbart — motstå den. Initial hastighet kan verka platt eller något lägre än förut. Det är normalt och förväntat. Agenter introducerar en ny typ av overhead: promptskapande, utdataanalys och korrigering. Benchmarkmålet här är adoptionskvalitet och felminskning, inte hastighet. Hastigheten kommer senare.
Vi tänker på detta stadium 1 som perioden när teamet utvecklar en ny professionell instinkt. Precis som en utvecklare som är ny i en kodbas läser mer än de skriver i början, korrigerar ett team som är nytt i AISDLC mer än det delegerar. Det är sunt. Målet är att lämna stadium 1 med ett tydligt, dokumenterat diagram över var agenter hjälper, var de faller kort, och hur bra agentutdata ser ut i din specifika kontext.
Stadium 1 — resultat
Agenter introduceras. Människor lär sig när de ska lita på, när de ska korrigera och hur man promptar effektivt. Förvänta dig friktion innan flöde.
Benchmarkmatris — Agentprestanda i Poddar
För varje rad, om du missar målet är kolumnen "vad det berättar för dig" inte kommentar — det är din diagnostiska startpunkt.
| Agent / Område | Vad man mäter | Mål | Vad det berättar för dig om du missar det |
|---|---|---|---|
| Kravagent | % av kravutkast accepterade utan större omskrivningar | 30–50% accepterade som de är | Agenten fångar inte avsikten korrekt. Kör en strukturerad promptgranskning — problemet är vanligtvis saknat sammanhang eller oklar omfångsöverlämning från människan. |
| Kravagent | % av krav med tvetydigheter flaggade innan arkitekturen börjar | 60%+ flaggade proaktivt | Agenten skickar vidare ofullständiga specifikationer nedströms. Luckor upptäcks för sent, i dev eller test, där de kostar mer att åtgärda. |
| Arkitekturagent | % av arkitekturförslag som överlever mänsklig granskning utan strukturella ändringar | 25–40% accepterade som de är | Agenten saknar tillräcklig kontext om begränsningar, icke-funktionella krav eller befintligt system. Människor behöver förinläsa mer begränsningsdokumentation. |
| Arkitekturagent | % av arkitekturbeslut spårbara tillbaka till ett dokumenterat krav | 85%+ spårbara | Agenter bygger utan grundad avsikt. Spårbarhetsluckor här blir omarbete i test eller efter driftsättning. |
| Utvecklaragent | % av agentgenererad kod accepterad utan betydande ändring | 20–35% accepterad som den är | Promptar eller arkitektonisk kontext som skickas till utvecklaragenten är otillräcklig. Kontrollera överlämningen mellan arkitektur och utvecklaragent. |
| Testagent | Körs testgenerering parallellt med dev, inte efter? | Ja, vid vecka 4 | Sekventiell test-efter-dev innebär att testagenten inte är integrerad i cykeln. Buggar kommer att klustras i slutet av sprinten snarare än att uppstå kontinuerligt. |
| Testagent | Buggantal per sprint uppdelat efter källa: agentintroducerade, människointroducerade, missade av testagenten | Spårat och uppdelat efter källa | Utan denna uppdelning kan du inte avgöra om buggar kommer från svagt dev-utdata, svaga promptar eller svag testtäckning. Alla tre ser likadana ut om du bara räknar totala buggar. |
| Agentsynk | Hur ofta får utvecklaragenten arkitekturkontext som är ofullständig eller motsäger kraven? | Mindre än 15% av uppgifterna | Det här är din primära synkroniseringsfelssignal. Höga frekvenser innebär att agenter arbetar i silos — krav-till-arkitektur-till-dev-överlämningskedjan är bruten. |
| Agentsynk | Tid mellan en kravsändring och att den förändringen återspeglas i arkitektur och testomfång | Samma sprint | Kravdrift som inte propageras är den vanligaste källan till omarbete i sen fas i Stadium 1. Om agenter inte uppdateras synkroniserat, ackumulerar du dold skuld. |
| Mänsklig tillsyn | % av agentöverlämningar mellan stadier som en människa granskar innan nästa agent fortsätter | 80%+ granskade | I Stadium 1 har förtroende ännu inte förtjänats. Ogranskade överlämningar förstärker fel över agenter. En bugg introducerad av kravagenten och inte fångad innan dev kan spridas genom alla återstående stadier. |
| Åsidosättningslogg | % av mänskliga åsidosättningar som identifierar vilken agent som orsakade korrigeringen, inte bara att en korrigering skedde | 80%+ agentattribuerade | Utan agentattribution kan du inte förbättra enskilda agenter. Du vet bara att systemet har brister, inte var. |
Benchmarkmatris — Mänskliga Interaktioner i Poddar
| Mått | Vad man frågar / spårar | Mål | Vad det berättar för dig om du missar det |
|---|---|---|---|
| Mänsklig känsla i podden | Veckovis pulsundersökning (1–5): "Agenterna i min pod gör mitt arbete lättare, inte svårare." Spårat per pod, inte genomsnitt för hela teamet. | 3,0+ vid vecka 4, trendar uppåt vid vecka 8 | En platt eller sjunkande poäng innebär att teamet absorberar agentoverhead utan att se avkastning. Problemet är vanligtvis dålig överlämningskvalitet eller agenter som genererar utdata som människan ändå måste bygga om från grunden. Om en pod scorer betydligt lägre än andra, undersök den podden specifikt — låt inte en högt scorande pod dölja en kämpalande. |
| Mänskligt förtroende för agentutdata | Veckovis pulsundersökning (1–5): "Jag känner mig trygg med att granska och korrigera agentutdata inom mitt område utan att det saktar ner mig." | 3,0+ vid vecka 6 | Lågt förtroende innebär att människor ännu inte kan utvärdera agentutdata kritiskt. Människor som saknar förtroende överkorrekt antingen allt eller godkänner saker de är osäkra på. Ingetdera är säkert i Stadium 1. |
| Ledtid: Krav till dev-klar | Dagar från att ett krav slutförs till att utvecklaragenten tar emot en komplett, godkänd brief. | Baslinje i vecka 1–2, förbättras sedan eller hålls stabilt | Om ledtiden ökar är överlämningen mellan krav och arkitektur flaskhalsen. En brief som tar längre tid att producera med agenter än utan är en tydlig signal att processen behöver omstruktureras, inte bara bättre promptar. |
| Eftersläpningstid: Buggupptäckt till lösning | Dagar från att en bugg flaggas av testagenten eller mänsklig granskare till att den lösts och stängts. | Inte sämre än baslinje före AISDLC | En växande eftersläpning innebär att buggar staplas upp snabbare än teamet kan hantera dem. I Stadium 1 innebär detta vanligtvis att testagenten körs för sent i cykeln — buggar hittas i batchar snarare än kontinuerligt. |
| Granskningslager (arbete i kö) | Antal agentutdata som ligger ogranskade av en människa i slutet av varje sprint — uppdelat per stadium: krav, arkitektur, dev, test. | Noll ogranskade utdata överförda till nästa sprint | Överfört lager är dold risk. Varje ogranskat agentutdata från nuvarande sprint blir ett sammansatt antagande i nästa. En växande kö innebär att människor är flaskhalsen — vilket är ett resurs- och processdesignproblem, inte ett teknologiproblem. |
En notering om åsidosättningsfrekvenser: En hög mänsklig åsidosättningsfrekvens i detta stadium är inte ett misslyckande — det är bevis på att teamet är engagerat och kritiskt granskar agentutdata. Den verkliga faran är det motsatta: mycket låga åsidosättningsfrekvenser kombinerat med dålig utdatakvalitet, vilket innebär att teamet stämplar allt. Om åsidosättningar sjunker under 20% under de första sex veckorna utan en motsvarande kvalitetsförbättring, undersök omedelbart.
Stadium 1 — Beredskapschecklista
Genomför en strukturerad retrospektiv vid 6-veckors- och 12-veckorsmärkena. För varje dimension i matrisen, markera den grön (vid mål), gul (inom 20% av mål), eller röd (ej spårad eller avsevärt avvikande). Använd checklistan nedan som din beredskapsport innan du går vidare till Stadium 2.
- Teamet kan tydliggöra vilka uppgifter agenter för närvarande hanterar och vilka de inte gör.
- Åsidosättningsfrekvenser spåras och minst 80% av åsidosättningarna har en dokumenterad anledning.
- Utvecklarsentimentpoäng är vid eller över 3,0 i genomsnitt.
- Felbinjektionsfrekvens har inte försämrats jämfört med baslinje före AISDLC.
- Minst en teammedlem har utsetts till AISDLC-praktisledare.
- Ett delat promptbibliotek har startats, även om det bara innehåller ett fåtal poster.
- Teamet har kommit överens om en kort lista över uppgifter som agenter inte får hantera autonomt.
Det enskilt mest värdefulla resultatet av Stadium 1
Det enskilt mest värdefulla resultatet av Stadium 1 är inte kod — det är loggen av åsidosättningar och korrigeringar. Den loggen är råmaterialet från vilket ditt team bygger sin agentdelegationsstrategi i Stadium 2. Team som hoppar över denna disciplin anländer till Stadium 2 utan en karta.
Det här pappret täcker Stadium 1 — Implementering. Fortsätt läsa för att utforska Stadium 2 — Lärande, där effektivitets- och kvalitetsförbättringar blir mätbara.