Oversikt
Å realisere den fulle verdien av AISDLC skjer ikke over natten. Uten tydelige markører risikerer team å forveksle aktivitet med fremgang. For å unngå dette identifiserte vi tre modenhetsstadier som gjenspeiler hvordan AISDLC-adopsjon realistisk sett utvikler seg. De er ikke rigide milepæler, men ærlige veivisere: blir vi bedre på dette, og blir vi bedre på de rette tingene?
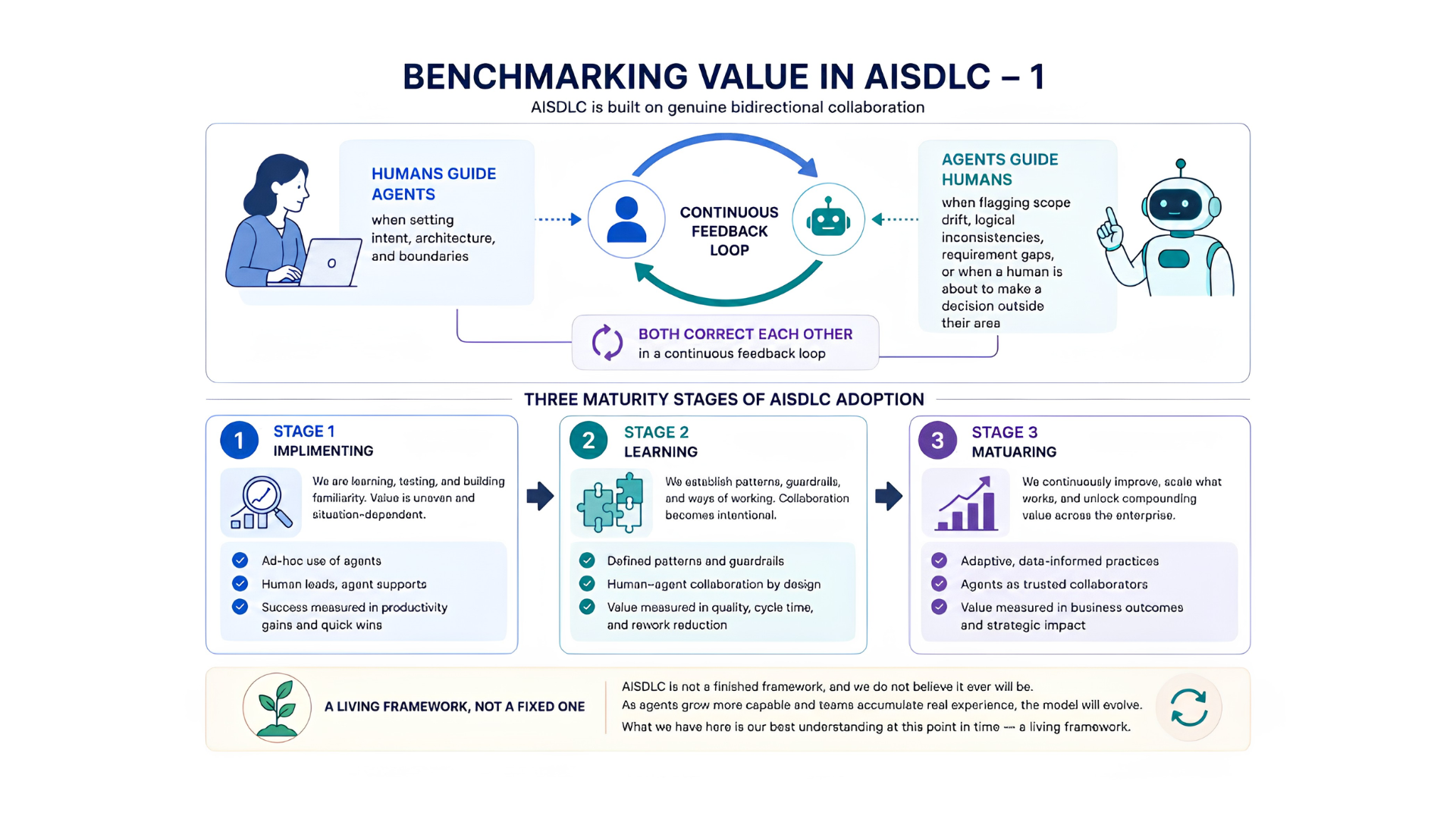
Det toveis Rammeverket
AISDLC er ikke et verktøy du installerer — det er et forhold du bygger. Målingsrammeverket er til for å gjøre det forholdet forståelig.
Som vi diskuterte i våre innsiktsartikler tidligere, er Aventude AISDLC fundamentalt bygget på toveis samarbeid der:
Hvordan samarbeidet fungerer i begge retninger
- Mennesker veileder agenter når de fastsetter intensjoner, arkitektur og grenser.
- Agenter veileder mennesker når de flagger omfangsdrift, logiske inkonsistenser, kravmangler, eller når et menneske er i ferd med å ta en beslutning utenfor sitt område.
- Begge korrigerer hverandre i en kontinuerlig tilbakemeldingssløyfe.
Det er også verdt å si tydelig: AISDLC er ikke et ferdig rammeverk, og vi tror ikke det noen gang vil bli det. Etter hvert som agenter blir mer kapable og team samler virkelig erfaring, vil modellen utvikle seg. Det som følger er vår beste forståelse på dette tidspunktet — et levende rammeverk, ikke et fast.
STADIUM 1
Implementering — Måneder 1 til 3. Adopsjonskvalitet og feilreduksjon, ikke hastighet.
STADIUM 2
Læring — Måneder 4 til 9. Effektivitets- og kvalitetsgevinster blir målbare.
STADIUM 3
Modnet — Måned 10 og fremover. AISDLC er driftsmodellen, ikke et eksperiment.
LEVENDE RAMMEVERK
Benchmarks kjøres med jevne mellomrom uavhengig av hvordan det føles.
Stadium 1 — Implementering (Måneder 1–3)
Det mest verdifulle som skjer i Stadium 1 er ikke å levere — det er teamets utvikling av vurderingsevne om hva agenter pålitelig kan og ikke kan gjøre.
Team integrerer agenter i sin eksisterende SDLC for første gang. Instinktet er å måle produktivitet umiddelbart — motstå det. Initial hastighet kan virke flat eller noe lavere enn før. Dette er normalt og forventet. Agenter introduserer en ny type overhead: promptutforming, utdatagjennomgang og korrigering. Benchmarkmålet her er adopsjonskvalitet og feilreduksjon, ikke hastighet. Hastigheten kommer senere.
Vi tenker på dette stadium 1 som perioden der teamet utvikler en ny profesjonell instinkt. Akkurat som en utvikler som er ny i en kodebase leser mer enn de skriver i begynnelsen, korrigerer et team som er nytt i AISDLC mer enn det delegerer. Det er sunt. Målet er å forlate stadium 1 med et tydelig, dokumentert diagram over der agenter hjelper, der de kommer til kort, og hva godt agentutdata ser ut som i din spesifikke kontekst.
Stadium 1 — resultat
Agenter introduseres. Mennesker lærer når de skal stole på, når de skal korrigere og hvordan man prompter effektivt. Forvent friksjon før flyt.
Benchmarkmatrise — Agentytelse i Podder
For hver rad, hvis du ikke når målet er kolonnen "hva det forteller deg" ikke kommentar — det er ditt diagnostiske startpunkt.
| Agent / Område | Hva som skal måles | Mål | Hva det forteller deg hvis du ikke når det |
|---|---|---|---|
| Kravagent | % av kravutkast akseptert uten store omskrivninger | 30–50% akseptert som de er | Agenten fanger ikke intensjonen korrekt. Kjør en strukturert promptgjennomgang — problemet er vanligvis manglende kontekst eller uklar omfangsoverlevering fra mennesket. |
| Kravagent | % av krav med tvetydigheter flagget før arkitektur begynner | 60%+ flagget proaktivt | Agenten sender ufullstendige spesifikasjoner nedstrøms. Mangler oppdages for sent, i utvikling eller test, der de koster mer å fikse. |
| Arkitekturagent | % av arkitekturforslag som overlever menneskelig gjennomgang uten strukturelle endringer | 25–40% akseptert som de er | Agenten mangler tilstrekkelig kontekst om begrensninger, ikke-funksjonelle krav eller eksisterende system. Mennesker må forhåndsinnlaste mer begrensningsdokumentasjon. |
| Arkitekturagent | % av arkitekturbeslutninger sporbare tilbake til et dokumentert krav | 85%+ sporbare | Agenter bygger uten grunnlagt intensjon. Sporbarhetsgap her blir omarbeiding i test eller etter utrulling. |
| Utvikleragent | % av agentgenerert kode akseptert uten vesentlig endring | 20–35% akseptert som den er | Prompter eller arkitektonisk kontekst som sendes til utvikleragenten er utilstrekkelig. Sjekk overleveringen mellom arkitektur og utvikleragent. |
| Testagent | Kjøres testgenerering parallelt med utvikling, ikke etter? | Ja, innen uke 4 | Sekvensiell test-etter-utvikling betyr at testagenten ikke er integrert i syklusen. Feil vil klynge seg på slutten av sprinten snarere enn å dukke opp kontinuerlig. |
| Testagent | Feilantall per sprint delt etter kilde: agentintroduserte, menneskeintroduserte, oversett av testagenten | Sporet og delt etter kilde | Uten denne inndelingen kan du ikke avgjøre om feil kommer fra svakt utviklingsutdata, svake prompter eller svak testdekning. Alle tre ser like ut hvis du bare teller totale feil. |
| Agentsynk | Hvor ofte mottar utvikleragenten arkitekturkontekst som er ufullstendig eller motsier kravene? | Mindre enn 15% av oppgavene | Dette er ditt primære synkroniseringsfeilsignal. Høye rater betyr at agenter opererer i siloer — krav-til-arkitektur-til-utvikling-overleveringskjeden er brutt. |
| Agentsynk | Tid mellom en kravsendring og at den endringen gjenspeiles i arkitektur og testomfang | Samme sprint | Kravdrift som ikke propageres er den vanligste kilden til sen-fase omarbeiding i Stadium 1. Hvis agenter ikke oppdateres synkront, akkumulerer du skjult gjeld. |
| Menneskelig tilsyn | % av agentoverleveringer mellom stadier som et menneske gjennomgår før neste agent fortsetter | 80%+ gjennomgått | I Stadium 1 er tillit ennå ikke opptjent. Ugjennomgåtte overleveringer forsterker feil på tvers av agenter. En feil introdusert av kravagenten og ikke fanget opp før utvikling kan spre seg gjennom alle gjenværende stadier. |
| Overstyrelogg | % av menneskelige overstyringer som identifiserer hvilken agent som forårsaket korrigeringen, ikke bare at en korrigering skjedde | 80%+ agentattribuert | Uten agentattribusjon kan du ikke forbedre individuelle agenter. Du vet bare at systemet har mangler, ikke hvor. |
Benchmarkmatrise — Menneskelige Interaksjoner i Podder
| Mål | Hva å spørre / spore | Mål | Hva det forteller deg hvis du ikke når det |
|---|---|---|---|
| Menneskelig stemning i podden | Ukentlig pulsundersøkelse (1–5): "Agentene i podden min gjør arbeidet mitt enklere, ikke vanskeligere." Sporet per pod, ikke gjennomsnitt for hele teamet. | 3,0+ innen uke 4, stigende trend innen uke 8 | En flat eller synkende poengsum betyr at teamet absorberer agentoverhead uten å se avkastning. Problemet er vanligvis dårlig overleveringskvalitet eller agenter som genererer utdata som mennesket fortsatt må bygge om fra bunnen. Hvis én pod scorer betydelig lavere enn andre, undersøk den podden spesifikt — ikke la en høytscorende pod maskere en slitende. |
| Menneskelig tillit til agentutdata | Ukentlig pulsundersøkelse (1–5): "Jeg føler meg trygg på å gjennomgå og korrigere agentutdata i mitt område uten at det bremser meg." | 3,0+ innen uke 6 | Lav tillit betyr at mennesker ennå ikke kan evaluere agentutdata kritisk. Mennesker som mangler tillit overkorrekt enten alt eller godkjenner ting de er usikre på. Ingen av delene er trygt i Stadium 1. |
| Ledetid: Krav til dev-klar | Dager fra et krav ferdigstilles til utvikleragenten mottar en komplett, godkjent brief. | Baslinje i uke 1–2, forbedres deretter eller holdes stabilt | Hvis ledetiden øker, er overleveringen mellom krav og arkitektur flaskehalsen. En brief som tar lengre tid å produsere med agenter enn uten er et tydelig signal om at prosessen trenger omstrukturering, ikke bare bedre prompter. |
| Etterslep: Feiloppdagelse til løsning | Dager fra en feil flagges av testagenten eller menneskelig gjennomgåer til den er løst og lukket. | Ikke verre enn baslinje før AISDLC | Et voksende etterslep betyr at feil hoper seg opp raskere enn teamet kan behandle dem. I Stadium 1 betyr dette vanligvis at testagenten kjøres for sent i syklusen — feil oppdages i partier snarere enn kontinuerlig. |
| Gjennomgangsbeholdning (arbeid i kø) | Antall agentutdata som ligger ugjennomgått av et menneske ved slutten av hver sprint — brutt ned etter stadium: krav, arkitektur, utvikling, test. | Null ugjennomgåtte utdata overført til neste sprint | Overført beholdning er skjult risiko. Hvert ugjennomgått agentutdata fra gjeldende sprint blir en sammensatt antagelse i neste. En voksende kø betyr at mennesker er flaskehalsen — noe som er et ressurs- og prosessdesignproblem, ikke et teknologiproblem. |
En merknad om overstyringsrater: En høy menneskelig overstyringsrate på dette stadiet er ikke en feil — det er bevis på at teamet er engasjert og kritisk gjennomgår agentutdata. Den virkelige faren er det motsatte: svært lave overstyringsrater kombinert med dårlig utdatakvalitet, noe som betyr at teamet stempelgodkjenner. Hvis overstyringer faller under 20% i de første seks ukene uten en tilsvarende kvalitetsforbedring, undersøk umiddelbart.
Stadium 1 — Beredskapssjekkliste
Gjennomfør en strukturert retrospektiv ved 6-ukers- og 12-ukersmerket. For hver dimensjon i matrisen, merk den grønn (på mål), gul (innenfor 20% av mål), eller rød (ikke sporet eller vesentlig avvikende). Bruk sjekklisten nedenfor som beredskapsporten din før du går videre til Stadium 2.
- Teamet kan tydeliggjøre hvilke oppgaver agenter for øyeblikket håndterer og hvilke de ikke gjør.
- Overstyringsrater spores og minst 80% av overstyringene har en dokumentert årsak.
- Utviklersentimentpoeng er ved eller over 3,0 i gjennomsnitt.
- Feilinjeksjonsrate har ikke forverret seg sammenlignet med baslinje før AISDLC.
- Minst ett teammedlem har blitt utpekt som AISDLC-praksisleder.
- Et delt promptbibliotek har blitt startet, selv om det bare inneholder et fåtall oppføringer.
- Teamet har blitt enige om en kort liste over oppgaver som agenter ikke har lov til å håndtere autonomt.
Det enkelt mest verdifulle resultatet av Stadium 1
Det enkelt mest verdifulle resultatet av Stadium 1 er ikke kode — det er loggen over overstyringer og korrigeringer. Den loggen er råmaterialet som teamet ditt bygger sin agentdelegasjonsstrategi i Stadium 2 fra. Team som hopper over denne disiplinen, ankommer Stadium 2 uten et kart.
Dette papiret dekker Stadium 1 — Implementering. Fortsett å lese for å utforske Stadium 2 — Læring, der effektivitet og kvalitetsforbedringer blir målbare.